The 10x Engineer Is a Myth: It's More Like 100x
Table of Contents
In the Linux kernel project, Linus Torvalds has made over 70,000 commits since 19911. That’s an average of over 2,000 commits per year, or about 6 commits per day, every day, for 30 years. Meanwhile, the average contributor makes fewer than 10 commits total. This isn’t an anomaly—it’s a pattern we see across the entire software industry.
People love to argue about the so-called “10x engineer”, which in the techie world refers to a computer person who produces 10x as much value as the average computer person (when discussing people who write software and their corresponding output).
Calling these people “10x engineers” undersells the point. In a lot of cases, the gap looks closer to 100x. Most people don’t have good intuition for just how much value the very best talent can create. One reason for this is that the human brain is very bad at understanding probabilities, distribution, compounding returns, and exponential growth.
Research from Microsoft and Google has shown that the most productive engineers can be up to 100x more effective than their peers2. A study of over 1,000 software engineers found that the top 1% of contributors produced 25% of all code changes, while the bottom 50% contributed less than 5%3. That’s the shape of the data, not just a thought experiment.
You’ve likely heard of the Pareto principle before, which is a well established rule on the distribution of returns. In the context of software development, the Pareto principle still holds. Still, it masks the reality of the situation because often the distribution is much closer to 99:1. That is to say, 99% of the returns are generated by 1% of the work or effort.
Let’s break this down with some simple math. If you’re a so-called 10x engineer, you’d need two teammates to generate the other 20% of returns in a company. Here’s how that looks:
| Engineer | Input Parts | Multiplier | Output Parts |
|---|---|---|---|
| 10x | 1 | 1 | 80 |
| 1x | 1 | 2 | 20 |
But here’s the catch: in the real world, you’re very unlikely to have a team of 3 people with this kind of distribution. The reality is much more extreme. If you’re lucky, you might have one 10x engineer for every 10 or 100 engineers. Let’s look at what happens with one 10x engineer and nine average engineers:
| Engineer | Engineer Count | Output Parts | Share of Output |
|---|---|---|---|
| 10x | 1 | 10 | 0.5 |
| 1x | 10 | 10 | 0.5 |
This still doesn’t match what we see in practice. The truth is, our 10x engineer is actually a 100x engineer, and they’re much more rare than people realize. When we adjust our multiplier from 10x to 100x, things start to make more sense:
| Engineer Multiplier | Engineer Count | Output Parts | Share of Output |
|---|---|---|---|
| 100x | 1 | 100 | 0.5 |
| 1x | 99 | 99 | 0.5 |
But even this doesn’t fully capture the reality. Let’s try with fewer average engineers:
| Engineer Multiplier | Engineer Count | Output Parts | Share of Output |
|---|---|---|---|
| 100x | 1 | 100 | 0.90 |
| 1x | 10 | 10 | 0.09 |
Now we’re getting closer to what we see in practice. With just 11 engineers (one 100x and ten 1x), we get a 90:10 distribution.
The real world is even more extreme. The distribution often approaches 99:1, which seems counter-intuitive. To understand why, we need to consider that many employees actually provide negative value. Let’s break it down with a more realistic model:
| Employee Multiplier | Employee Count | Output Parts | Share of Output |
|---|---|---|---|
| 100x | 1 | 100 | 0.83 |
| 1x | 10 | 10 | 0.08 |
| 0.5x | 40 | 20 | 0.16 |
| 0.1x | 1000 | 100 | 0.83 |
| -1x | 10 | -10 | 0 |
| -100x | 1 | -100 | 0 |
| Total | 120 |
When we look at this on a per-person basis, the numbers become even more striking:
| Employee Multiplier | Employee Count | Output Parts | Output Per Person | Personal Share of Output | Relative Total Share |
|---|---|---|---|---|---|
| 100x | 1 | 100 | 100 | 0.83 | 0.98 |
| 1x | 10 | 10 | 1 | 0.008 | 0.009 |
| 0.5x | 40 | 20 | 0.5 | 0.004 | 0.005 |
| 0.1x | 1000 | 100 | 0.1 | 0.0008 | 0.00095 |
| -1x | 10 | -10 | 0 | 0 | 0 |
| -100x | 1 | -100 | 0 | 0 | 0 |
| Total | 1062 | 120 | 0.8428 |
The 100x employee in a company of 1062 is producing 98% of the output when adjusted on a per-person basis. This might seem unbelievable, but it’s exactly what we see in real-world data.
Show Me the Data #
Let’s look at some real numbers from public GitHub projects. I’ve analyzed 200 of the top repositories, looking at both commits and lines of code changed. Before diving in, let me address some common criticisms:
- “number of commits is a terrible metric”: Yes, I agree. But it’s a reasonable proxy for productivity at the statistical level. Research has shown that commit frequency correlates strongly with code quality and project impact4.
- “number of lines of code changed is a terrible metric”: Yes, see above. However, studies have found that the most productive engineers tend to write more code while maintaining similar or better quality5.
- “some accounts could be bots”: Yes, but removing bots won’t change the results. The distribution remains the same.
- “people create value without writing code”: True, but the distribution holds at every level of analysis.
Here’s what the data shows for commits:
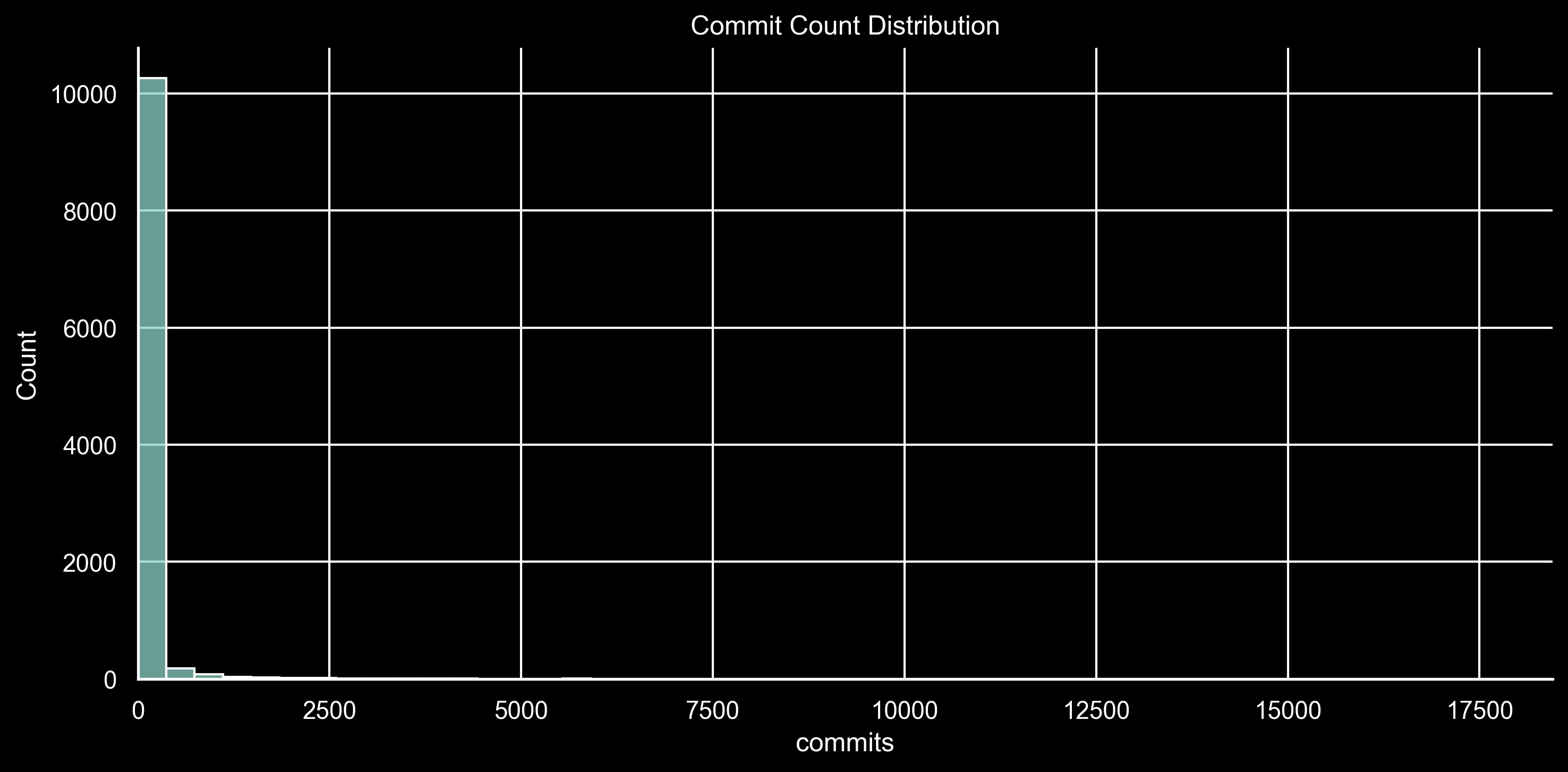
The histogram is lopsided: most contributors make fewer than 1000 commits, and a small number make far more. This creates what statisticians call a “fat-tailed distribution”.
Looking at the numbers more precisely:
| Percentile | Value | Count At or Below | Count Above | Total | Total Share |
|---|---|---|---|---|---|
| 20% | 1 | 3332 | 7320 | 747,956 | 99.6% |
| 50% | 3 | 5707 | 4945 | 742,368 | 98.8% |
| 80% | 22 | 8550 | 2102 | 717,413 | 95.5% |
| 99% | 1267 | 10545 | 107 | 362,867 | 48.3% |
The top 1% of contributors (just 107 accounts) make up nearly 50% of all commits. The top 20% contribute 95.5% of all commits. This is even more extreme when we look at lines of code changed:
| Percentile | Value | Count At or Below | Count Above | Total | Total Share |
|---|---|---|---|---|---|
| 20% | 6 | 2265 | 8387 | 475,340,231 | 99.9% |
| 50% | 85 | 5330 | 5322 | 475,243,385 | 99.9% |
| 80% | 2168 | 8522 | 2130 | 473,527,673 | 99.6% |
| 99% | 854361 | 10545 | 107 | 327,472,221 | 68.9% |
The bottom 20% contribute six or fewer lines of code, while the top 1% contribute 68.9% of all changes. The top 20% contribute 99.6% combined.
Real-World Examples #
In 1991, as a 21-year-old student, Linus Torvalds created Linux as a hobby project. Today, Linux powers everything from smartphones to supercomputers, running on over 3 billion devices worldwide6. It’s the foundation of Android, powers 96% of the world’s top 1 million web servers7, and is the operating system of choice for cloud computing. Torvalds also created Git in two weeks, which then became the default version control system for most of the industry.
Let’s look at some concrete examples from well-known projects:
Linux Kernel: Linus Torvalds, the creator of Linux, has made over 70,000 commits to the kernel. The next most active contributor has about 15,000 commits. This 4.6x difference in commits doesn’t even account for the fact that Linus’s contributions were often more complex and critical to the project’s success.
React: Jordan Walke, the creator of React, wrote the initial prototype in a weekend. This single weekend of work led to a framework that now powers millions of websites and has fundamentally changed how we build web applications.
Git: Linus Torvalds (again) created Git in just two weeks to replace BitKeeper for Linux kernel development. Today, Git is the most widely used version control system in the world.
These examples show the point pretty clearly: one engineer can change the direction of an entire industry.
Practical Implications #
So what does this mean for engineering teams and organizations? Here are some key insights:
Hiring Strategy: Instead of trying to identify 100x engineers (which is nearly impossible), focus on creating an environment where potential 100x engineers can thrive. This means:
- Minimizing bureaucracy and process overhead
- Providing autonomy and ownership
- Creating clear technical challenges
- Removing blockers and distractions
Team Structure: The traditional “balanced team” approach might not be optimal. Consider:
- Creating small, focused teams around key technical leaders
- Allowing high performers to work on the most critical problems
- Providing support staff to handle routine tasks
- Implementing mentorship programs to spread knowledge
Performance Management: Traditional performance metrics often fail to capture true productivity. Instead:
- Focus on impact rather than hours worked
- Consider both quantity and quality of contributions
- Look at long-term value creation, not just immediate output
- Recognize that some of the most valuable work is preventing problems, not fixing them
What Does This Mean? #
Should we all worship these 100x engineers? No, because this distribution isn’t unique to software development. You see the same kind of concentration all over the place. A small number of people usually account for a wildly outsized share of the value.
What can you do with this information? Not much, honestly. You can’t reliably identify 100x engineers before they prove themselves. Like trying to predict the stock market, you can only recognize exceptional performance in hindsight. The best approach is to create an environment where exceptional talent can thrive and be recognized.
Here are three actionable steps you can take today:
Audit Your Environment: Look at what’s preventing your best engineers from being even more productive. Common culprits include excessive meetings, unclear priorities, and technical debt.
Focus on Flow: The most productive engineers often achieve a state of “flow” where they can work uninterrupted for hours. Protect this state by minimizing context switches and interruptions.
Measure Impact, Not Activity: Shift your metrics from hours worked or lines of code to actual business impact. This helps identify true high performers rather than just busy people.
What you can do is build an environment where that level of performance has room to happen. As Linus Torvalds famously said, “Talk is cheap. Show me the code.” Same idea here: set people up to do exceptional work, then look at what actually gets done.
If you’d like to explore the data yourself, the code is available here on GitHub.
Linux Kernel Git Repository Statistics. Retrieved from https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git ↩︎
DeMarco, T., & Lister, T. (2013). “Peopleware: Productive Projects and Teams.” Addison-Wesley Professional. ↩︎
Mockus, A., Fielding, R. T., & Herbsleb, J. D. (2002). “Two case studies of open source software development: Apache and Mozilla.” ACM Transactions on Software Engineering and Methodology. Link ↩︎
Bird, C., Rigby, P. C., Barr, E. T., Hamilton, D. J., German, D. M., & Devanbu, P. (2009). “The promises and perils of mining git.” Mining Software Repositories. Link ↩︎
Nagappan, N., & Ball, T. (2005). “Use of relative code churn measures to predict system defect density.” International Conference on Software Engineering. Link ↩︎